
Feedback Loops in Generative AI: How AI May Shoot Itself in the Foot

Content generated by AI has become ubiquitous, particularly on the Internet, which serves as a major source of data for training generative AI models¹ ². This creates a long-term threat to the performance of the generative AI models themselves.

1. What is a feedback loop?
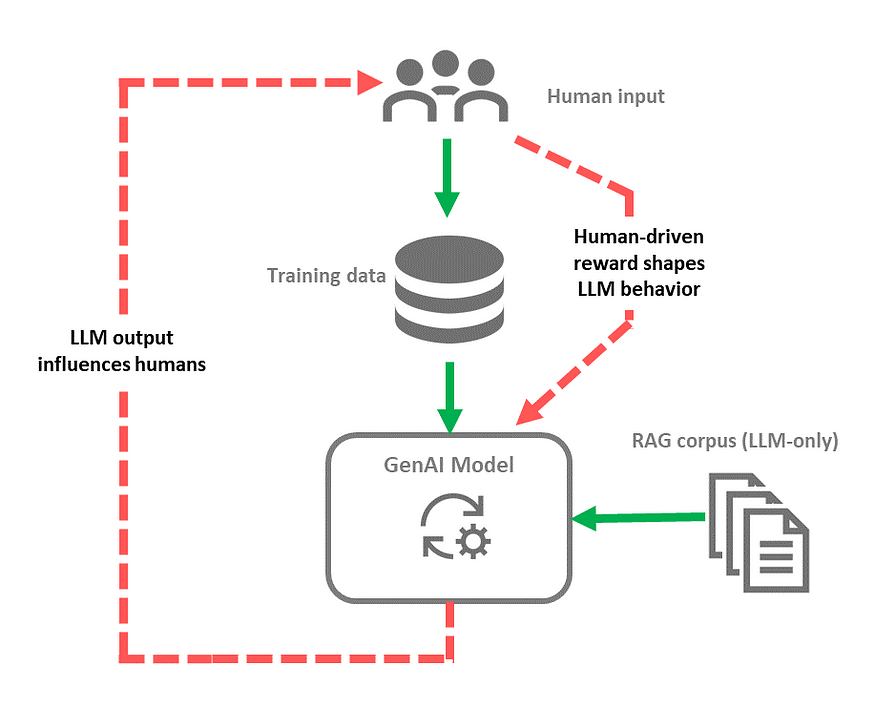
While many variations and nuances exist, the basic process of building a generative AI model consists of collecting content — usually human-created content — from various sources before training the foundational model.
The model can then be fine-tuned using techniques such as supervised fine-tuning, reinforcement learning with human feedback or Low-Rank Adaptation³ to make it better suited for a specific application. In the case of Large Language Models (LLMs), Retrieval-Augmented Generation (RAG)⁴ is also often used to search for relevant information on the fly. Then, given a new prompt, the model can generate novel content.
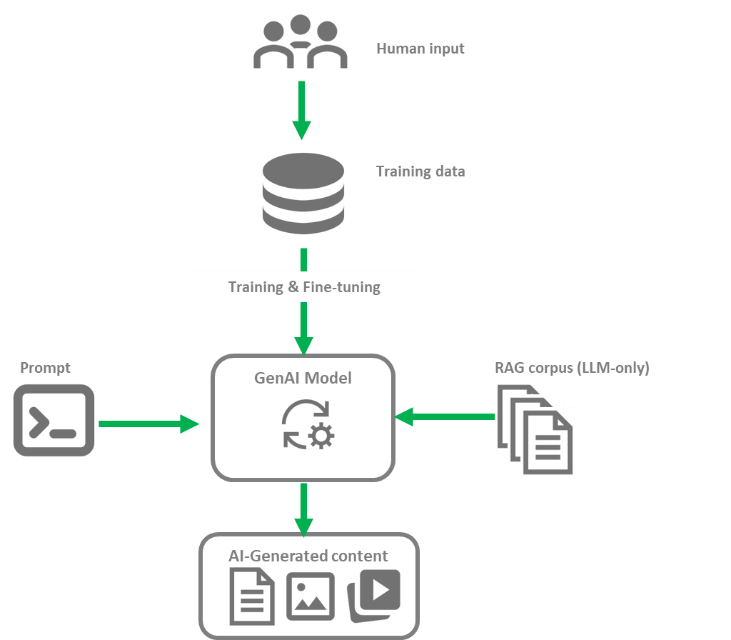
In this process, the quality of the data used for training, fine-tuning and the information retrievable using RAG for LLMs are key-determinants of the quality of the model output.
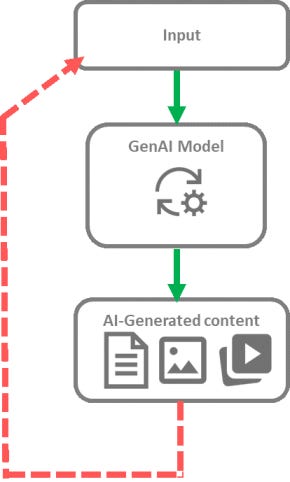
Feedback loops originally designated situations where AI-generated content is used to train new models². Similar mechanisms have since been described where generated content influences, directly or indirectly, the creation of new AI-generated content. Consequently, the terms ‘feedback loop’, ‘autophagous loop’ or ‘self-referential learning loop’⁵ are now used for any situation where past outputs of a model play a role in the generation of future outputs.
2. Main Feedback Loop Mechanisms
Training Dataset Contamination
The availability of vast amounts of data on the Internet is one of the key factors that has contributed to the emergence of generative AI as large training datasets extracted from the Internet allowed training models that can now generate new content. In turn, this AI-generated content can be published on the Internet, with or without human reworking and curation. Consequently, AI-generated content ends up in the same source of information from which the initial training dataset was extracted, implying that future iterations of generative AI models and new models will be trained on a blend of human-generated and synthetic content².
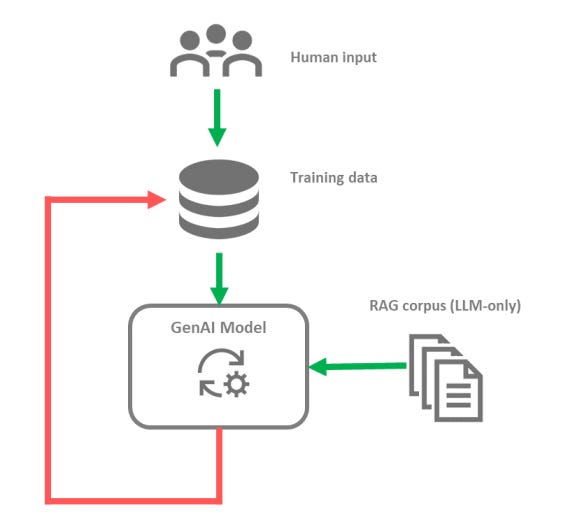
RAG Contamination
The Internet is not only a source of data for training generative AI models. In the case of the Large Language Models, it is also used as a source of information. Consequently, Retrieval-augmented Generation (RAG) based on web search can lead a Large Language Model to generate answers based on information that was already AI-generated in the first place⁶.
This principle can also apply if the RAG process is grounded on a knowledge base or another documentation pool. If part of the information contained in this information repository has been generated by AI, it can play a role in the generation of new outputs.
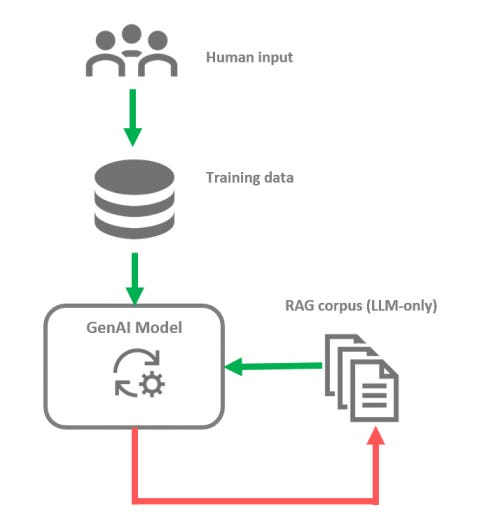
Human-AI interaction
Another type of feedback loop is linked to human-AI interactions. It is now clear that AI-generated material can influence humans. Hallucinations or voluntary misinformation are well-documented phenomena, and their influence can be very tangible. For instance, a study has shown that propaganda material created by AI can be as effective as propaganda material generated by humans⁷. The influence of AI also shapes human perception and even amplifies biases, triggering a feedback loop that could amplify biases or perpetuate false beliefs or erroneous information over time⁸. In turn, humans will generate content influenced by previous AI outputs. Therefore, genuine human-generated content may not be free of AI influence from past interactions.
Humans can also directly influence the general behavior of an AI system in cases where this system receives rewards that are driven by humans. This type of process can lead to ‘reward-hacking’ behavior, in which the AI system maximizes rewards by adopting unwanted behaviors. An example described by Pan et al⁹. is an agent that generates tweets and receives a reward based on user engagement. This generative AI system could tend to create more controversial or toxic content, for instance, at the expense of factual accuracy.
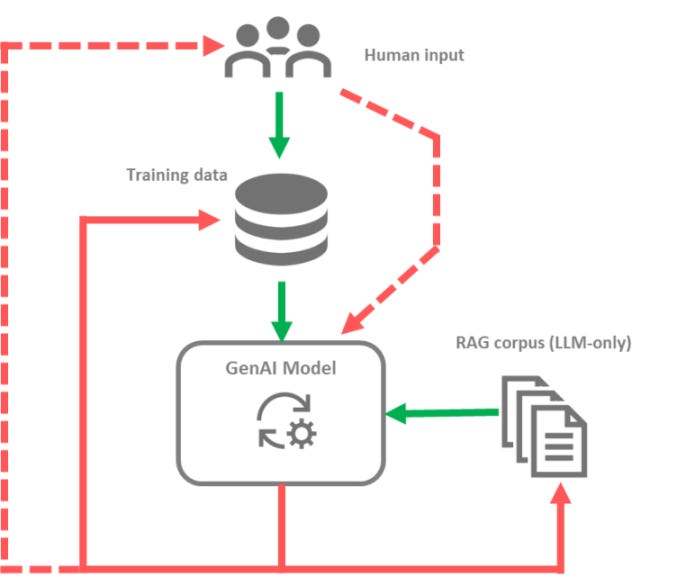
Combined feedback loops and cumulative effect
It is important to keep in mind that these feedback loops can coexist simultaneously. In this case, the 3 types of feedback loops may be at work in parallel.
They also have a cumulative effect over time, with the risk of observing the diminishing presence of original human-created content amid the proliferation of AI-generated material.
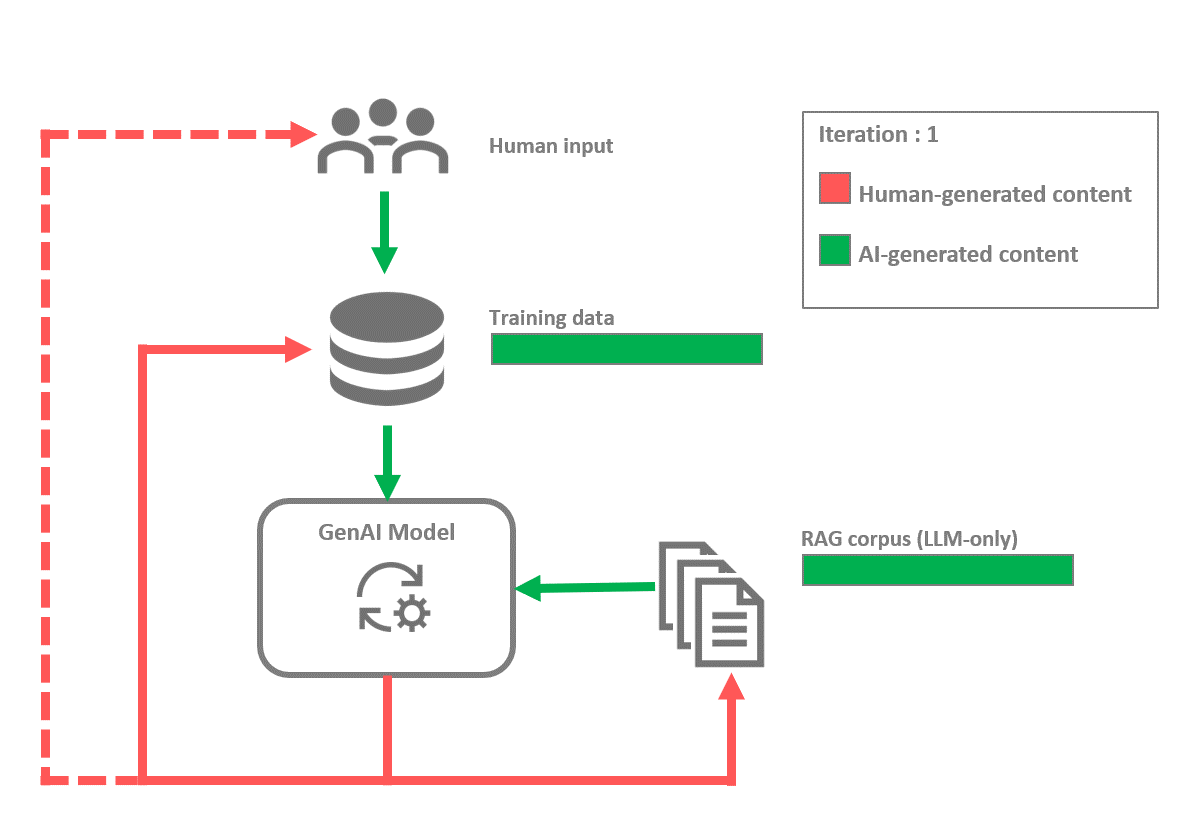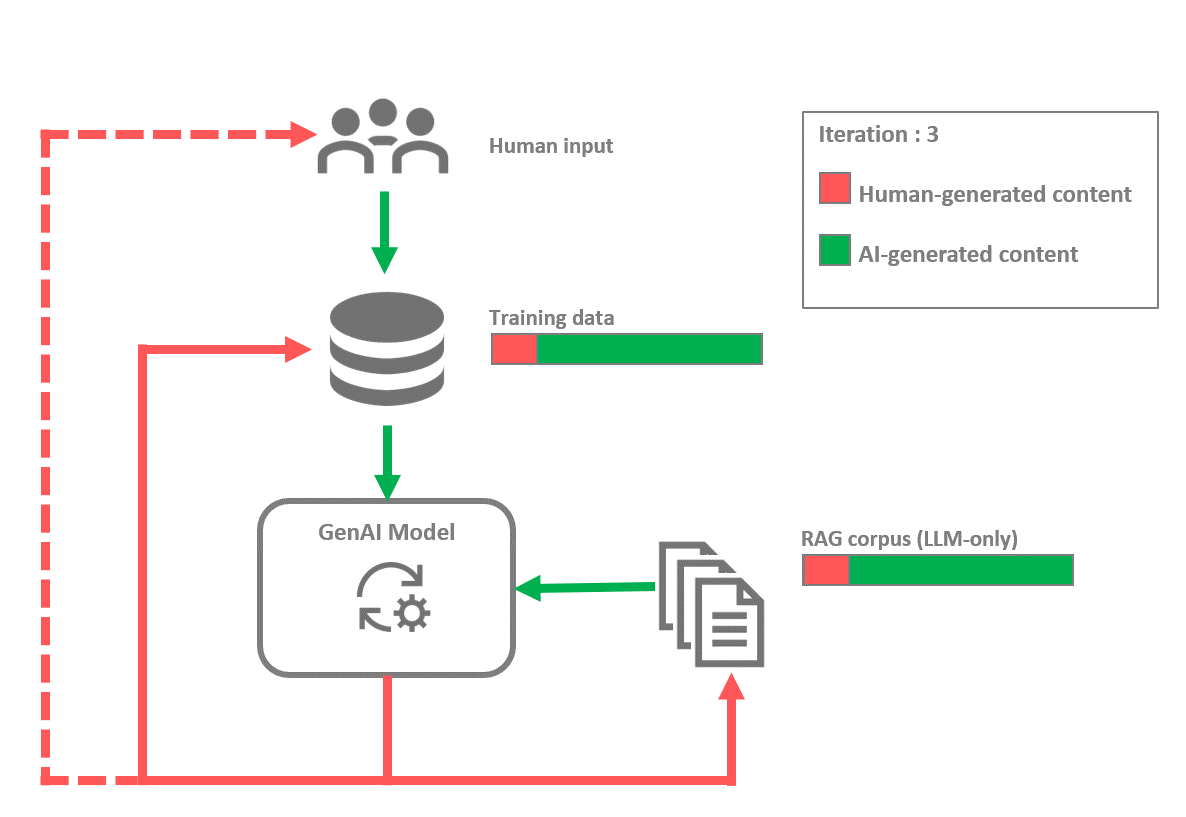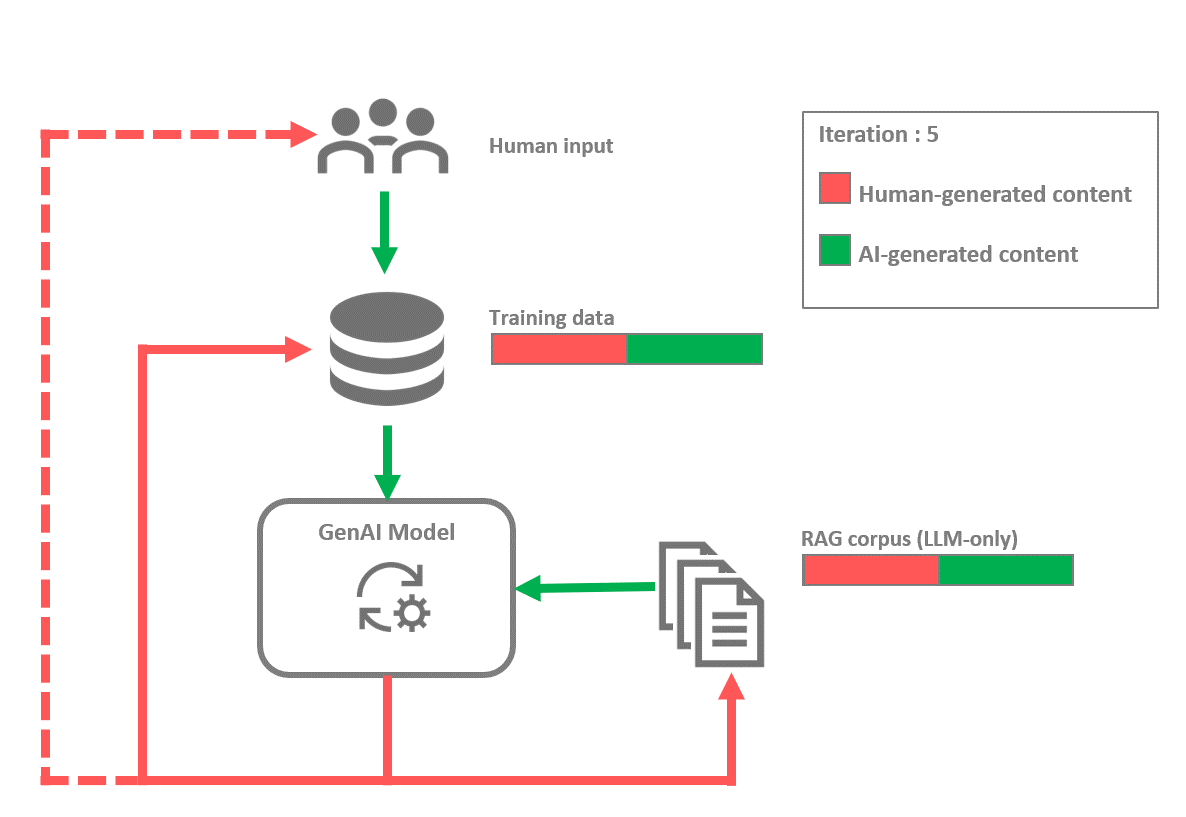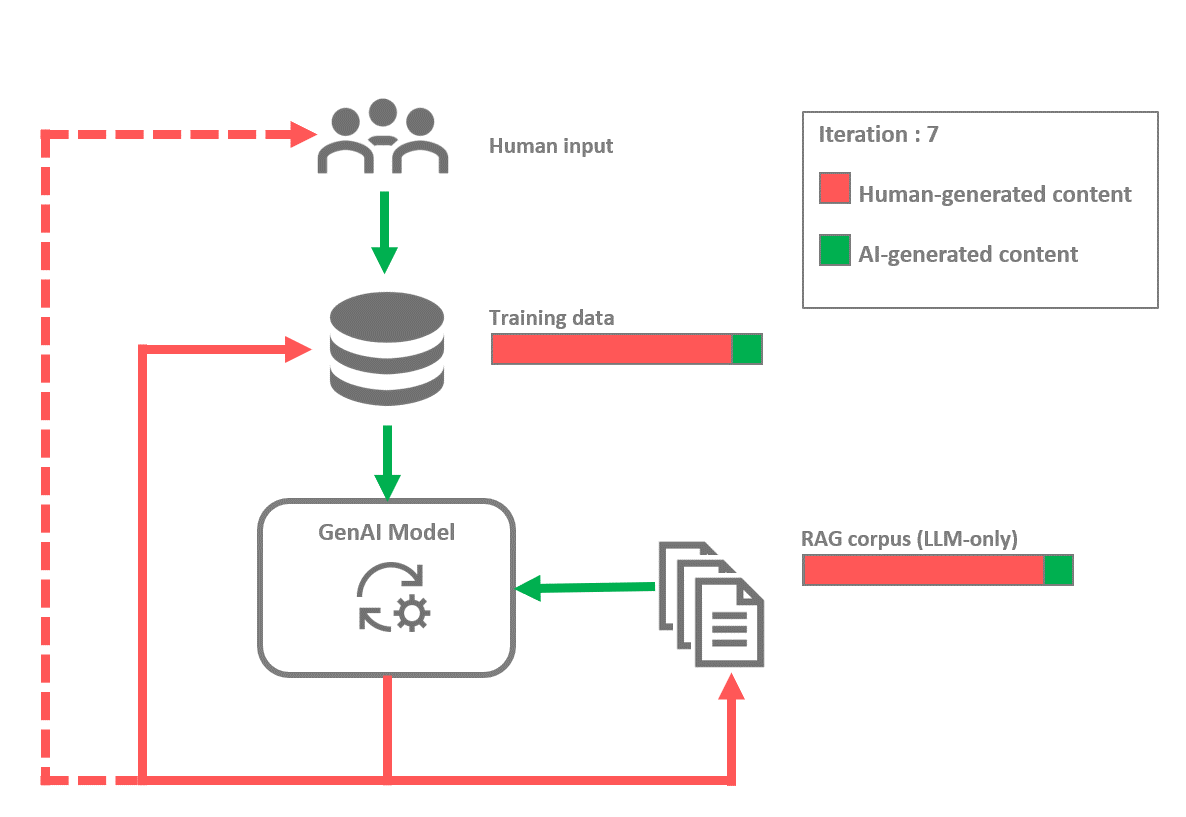
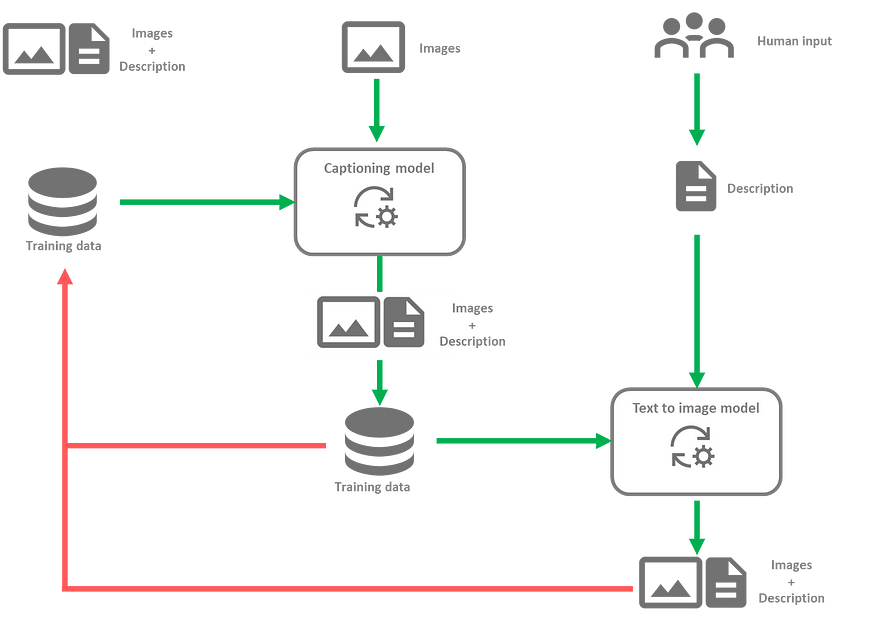
More complex feedback loops can also appear, particularly in cases where several models and modalities are involved. For instance, consider the case where an image captioning model, trained on sets of images along with their descriptions, is used to generate detailed descriptions of other images. These descriptions are then used to train a text-to-image diffusion model, which eventually generates new images based on new descriptions. This process is similar to the workflow used to train DALL-E 3¹⁰. The image captioning model obviously influences the text-to-image model. Therefore, if the image captioning model is subject to a feedback loop, this will in turn affect the text-to-image model. Such a feedback loop could manifest particularly if future iterations of the image captioning model are trained on datasets containing sets of images with descriptions it has generated, or images that have been generated by the downstream text-to-image model.
3. Consequences
Feedback loops in generative AI are an active field of study. The implications are not fully understood yet. Nonetheless, problematic consequences have been described, including the aspects outlined hereafter:
AI collapse¹¹: This refers to the progressive degradation of a model’s performance over multiple generations, where the model eventually only generates a reduced set of outputs or very similar outputs, to the point where it becomes unusable¹². The phenomenon is sometimes characterized by a regression-to-the-mean behavior, but the distribution of the data may eventually bear little resemblance to the initial training data distribution.
Spiral of silence or ‘echo-chamber effect⁶: This effect occurs when the rapid production of content by large language models (LLMs) results in the marginalization of human-created content, minority opinions, or novel content. This effect is potentially compounded by a bias of search algorithms towards LLM-generated texts, eventually leading to the persistence of outdated content, delayed emergence of new knowledge, non-representation of minority opinions, and possibly the dissemination of factual inaccuracies.
Bias amplification¹³: Not only do generative AI models replicate biases, but they also tend to amplify these biases. This leads to the under-representation of certain classes and the reliance on stereotypes and prejudices. Due to the cumulative effect of feedback loops over multiple model generations, such biases could be exacerbated over time¹⁴.
Decreasing quality and diversity of images²: Generative AI models may produce lower quality and less diverse images over time, including the appearance of artifacts¹⁵.

Training generative artificial intelligence (AI) models on synthetic data progressively amplifies artifacts. In this case, cross-hatched artifacts (source : https://arxiv.org/pdf/2307.01850)

Though it has not been extensively studied, it is reasonable to think that the progressive decrease in quality and loss of diversity is likely to extend to models generating video and audio as well.
Constraint violations: Generative AI models might generate toxic content or lose alignment with intended constraints, particularly if the output can lead to a reward for the model⁹.
4. Mitigation
As the study of feedback loops in generative AI is an active field of research, no consensus for a practical solution has emerged yet. Nonetheless, a few notable proposed approaches can provide insights toward the mitigation of feedback loops.
Watermarking and synthetic data filtering
An intuitive way to mitigate the risk of feedback loops in generative AI would be to prevent the usage of synthetic content in training datasets and for RAG. Unfortunately, identifying synthetic content that is not clearly marked as such has proven to be unreliable. As models progress, this task is bound to become even more difficult. Nonetheless, watermarking synthetic content could be a solution for certain types of content such as images, audio, and video in training datasets. Expecting 100% of synthetic content to be watermarked is unrealistic, but having watermarking implemented by major model providers would be beneficial in the long term. The emergence of a consensus on a standard watermarking technique, or at least a limited number of watermarking types, could help reduce the prevalence of synthetic content in training datasets even further.
Controlled non-biased real data intake
If we can’t completely prevent feedback loops, all hope is not lost. Research suggests that a limited amount of synthetic data is acceptable as long as a sufficient amount of new real data is added at each iteration. In fact, a limited amount of synthetic data can even improve performance when the availability of real data is limited. Nonetheless, evaluating the actual amount of admissible synthetic data is complex and still not well understood. It appears to depend not only on the amount of fresh real data but also on the sampling technique used to gather this data. Notably, a study from 2023 suggests that, in the case of image generation models, using sampling bias on the real data — such as keeping pictures that are ‘good-looking’ — decreases the amount of synthetic data that can be tolerated without affecting performance¹⁵.
Therefore, the impact of feedback loops could potentially be mitigated by limiting the intake of potentially synthetic data and ensuring a sufficient input of fresh real data at each iteration, while limiting the sampling bias for real data. If these observations extend to LLMs, it could translate to removing any further filtering of content identified as predominantly human-generated and allowing a certain amount of potentially synthetic data, based on the estimate of fresh real data. The model behavior can then be adjusted through fine-tuning, and the source selection based on quality can focus on the data used for RAG.
Mitigating bias amplification using calibrated models
A calibrated model generates output whose statistical distribution is equivalent to the training dataset. For a generative AI system, this means that the outputs are representative of the training dataset. Most generative AI models are not well calibrated¹³. They tend to be ‘overconfident’ and focus on sample types that are over-represented in the training dataset, making their output more representative of this subset of the training data. As a result, they amplify any bias present in the initial data, and this bias amplification compounds over time in the case of feedback loops. Unfortunately, while it helps mitigate the effects of feedback loops, training large language models and other generative models to be well-calibrated is difficult to achieve in practice¹⁶. Additionally, the calibration of an LLM can be influenced by hyperparameters controlled by the user, particularly the model’s temperature¹⁷.
It should be noted here that measures aiming at compensating for a bias present in the dataset or the prompt can also be problematic in the context of feedback loops, as they could lead to other compensations over time.
Conclusion
Feedback loops in generative AI are a multi-faceted problem that is still not fully understood, and robust mitigation strategies are currently lacking. Current generative AI model architectures require fresh human-generated data to improve, yet this data is becoming increasingly difficult to collect due to the proliferation of AI-generated content. This phenomenon could be a limiting factor for AI progress in the years to come, as some predict we could be running out of high-quality language by the end of 2024¹¹.
Nonetheless, most studies to date have considered the case of one model being fed content created by its previous version. However, in reality, several models generating the same modality could feed each other. For instance, the training dataset for Llama could include text generated by ChatGPT, the training dataset for Gemini could include text generated by Llama, and the training dataset for ChatGPT could include text generated by Gemini. This cross-feeding situation is more representative of reality, yet its consequences have not been studied in depth.
References
[1] OpenAI. GPT-4 System Card OpenAI.; 2023. https://cdn.openai.com/papers/gpt-4-system-card.pdf
[2] Martínez G, Watson L, Reviriego P, Alberto Hernández J, Juarez M, Sarkar R. Towards Understanding the Interplay of Generative Artificial Intelligence and the Internet.; 2023. https://arxiv.org/pdf/2306.06130
[3] Hu E, Shen Y, Wallis P, et al. LORA: LOW-RANK ADAPTATION of LARGE LANGUAGE MODELS.; 2021. https://arxiv.org/pdf/2106.09685
[4] Lewis P, Perez E, Piktus A, et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.; 2021. https://arxiv.org/pdf/2005.11401
[5] Choudhury A, Chaudhry Z. Large Language Models and User Trust: Consequence of Self-Referential Learning Loop and the Deskilling of Healthcare Professionals. Journal of Medical Internet Research. 2024;26:e56764. doi:https://doi.org/10.2196/56764
[6] Chen X, He B, Lin H, et al. Spiral of Silence: How Is Large Language Model Killing Information Retrieval?-A Case Study on Open Domain Question Answering. Accessed August 2, 2024. https://arxiv.org/pdf/2404.10496
[7] Goldstein JA, Chao J, Grossman S, Stamos A, Tomz M. How persuasive is AI-generated propaganda? PNAS nexus. 2024;3(2). doi:https://doi.org/10.1093/pnasnexus/pgae034
[8] Glickman M, Tali Sharot. Biased AI systems produce biased humans. Published online November 15, 2022. doi:https://doi.org/10.31219/osf.io/c4e7r
[9] Pan A, Jones E, Jagadeesan M, Steinhardt J. Feedback Loops with Language Models Drive In-Context Reward Hacking. Accessed August 2, 2024. https://arxiv.org/pdf/2402.06627
[10] Betker J, Goh G, Jing L, et al. Improving Image Generation with Better Captions.; 2023. https://cdn.openai.com/papers/dall-e-3.pdf
[11] Artificial Intelligence Index Report 2024. https://aiindex.stanford.edu/wp-content/uploads/2024/04/HAI_2024_AI-Index-Report.pdf
[12] Model Collapse Demystified: The Case of Regression. arxiv.org. Accessed August 2, 2024. https://arxiv.org/html/2402.07712v1
[13] Hall M, Ai M, Laurens Van Der Maaten U, et al. A Systematic Study of Bias Amplification. https://arxiv.org/pdf/2201.11706
[14] Wyllie S, Shumailov I, Papernot N. Fairness Feedback Loops: Training on Synthetic Data Amplifies Bias.; 2024. Accessed May 24, 2024. https://arxiv.org/pdf/2403.07857
[15] Alemohammad S, Casco-Rodriguez J, Luzi L, et al. Self-Consuming Generative Models Go MAD.; 2023. https://arxiv.org/pdf/2307.01850
[16] Taori R, Hashimoto T. Data Feedback Loops: Model-Driven Amplification of Dataset Biases. https://arxiv.org/pdf/2209.03942
[17] Huang Y, Liu Y, Thirukovalluru R, Cohan A, Dhingra B. Calibrating Long-Form Generations from Large Language Models. Accessed August 2, 2024. https://arxiv.org/pdf/2402.06544