
5' Research Brief - Expert-Guided Explainable Few-Shot Learning for Medical Image Diagnosis
5 Minutes to get the key ideas.
Original Article: “Expert-Guided Explainable Few-Shot Learning for Medical Image Diagnosis”
Authors: Ifrat Ikhtear Uddin, Longwei Wang, KC Santosh
Source: ArXiv (Link)
Introduction
Medical AI faces a fundamental challenge: achieving high diagnostic accuracy with limited expert-annotated data while maintaining clinical interpretability. Traditional deep learning models require extensive labeled datasets, but medical imaging often provides only a few annotated examples per diagnostic category. Even when few-shot learning models achieve reasonable accuracy, they typically lack transparency in their decision-making processes, making clinicians hesitant to trust their predictions. This study addresses both limitations simultaneously by proposing an expert-guided explainable few-shot learning framework that integrates radiologist-provided regions of interest (ROIs) directly into model training to enhance both classification performance and interpretability.
Objective
The primary goal was to develop a few-shot learning framework that could:
• Learn effectively from limited medical imaging data (3-way, 3-shot scenarios)
• Align model attention with clinically meaningful regions identified by radiologists
• Simultaneously improve classification accuracy and visual interpretability
• Bridge the gap between AI performance and clinical trustworthiness in data-constrained healthcare settings
The authors hypothesized that incorporating expert spatial guidance during training would encourage models to focus on diagnostically relevant features, leading to better generalization and more reliable explanations than conventional few-shot approaches.
Proposed Solution
The framework combines prototypical networks with expert-guided attention supervision through several core techniques:
• Prototypical Network Foundation: Uses DenseNet-121 as a feature extractor to learn class prototypes from support samples, enabling few-shot classification based on Euclidean distance metrics
• Grad-CAM Integration: Generates attention heatmaps during training to visualize which image regions influence model predictions
• Novel Explanation Alignment Loss Function: Introduces a Dice similarity-based loss function that measures alignment between Grad-CAM heatmaps and radiologist-provided ROIs, penalizing attention to clinically irrelevant regions
• Joint Optimization Objective: Combines standard prototypical classification loss with the explanation alignment loss (weighted by hyperparameter α) to simultaneously optimize accuracy and interpretability.
Evaluation Approach
The authors conducted experiments on two distinct medical imaging datasets:
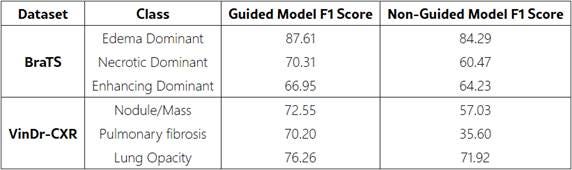
• BraTS Dataset (Brain MRI): Multi-modal brain tumor scans with expert segmentation masks for tumor subregions (edema, necrotic, and enhancing areas).
• VinDr-CXR Dataset (Chest X-rays): Frontal chest radiographs with radiologist-annotated bounding boxes for thoracic abnormalities including nodule/mass, pulmonary fibrosis, and lung opacity
Training Protocol: 3-way, 3-shot episodic training with 9 support and 9 query samples per episode, trained for 7 epochs with 60 episodes each. Models compared included non-guided baselines (standard prototypical networks) versus guided models trained using the Joint Optimization Objective (including Explanation Alignment Loss)
Evaluation Metrics: Overall accuracy, class-wise F1-scores for quantitative assessment, and qualitative Grad-CAM visualization comparison for interpretability analysis.
Results
The expert-guided framework demonstrated substantial improvements across both datasets:
Classification Performance:
• BraTS dataset: Accuracy increased from 77.09% to 83.61%
• VinDr-CXR dataset: Accuracy improved from 54.33% to 73.29%
• Class-wise F1-scores showed consistent improvements across all diagnostic categories
Optimal Hyperparameter: The explanation weight α = 0.10 provided the best balance between classification accuracy and attention alignment. Both lower and higher values led to performance degradation, indicating the importance of moderate explanation guidance.

Interpretability Enhancement: Grad-CAM visualizations revealed that guided models consistently focused on diagnostically relevant regions aligned with expert annotations, while non-guided models often highlighted clinically irrelevant areas despite achieving reasonable classification accuracy.


Why This Matters
This research addresses several critical challenges in medical AI deployment:
Enhanced Data Efficiency: By achieving significant accuracy improvements with minimal training data (3 samples per class), the framework addresses the practical reality of limited annotated medical datasets, making AI more accessible for rare conditions or resource-constrained settings.
Clinical Trust and Adoption: The integration of expert knowledge into model training creates AI systems whose decision-making processes align with clinical reasoning, potentially increasing physician confidence and adoption rates in real-world healthcare settings.
Interpretable AI for Safety-Critical Applications: Unlike post-hoc explanation methods, this approach embeds interpretability directly into the learning process, ensuring that high-performing models also provide clinically meaningful explanations essential for medical decision-making.
Scalable Expert Knowledge Integration: The framework provides a practical method for incorporating domain expertise into AI training without requiring extensive additional annotation efforts, making it feasible for broader clinical implementation across different medical specialties and imaging modalities.
To Go Further
If you wish to go beyond this overview, the complete paper can be found at: […]
Note: Unless stated otherwise, all images presented in this article are derived from the original work by Uddin et al.
Key Terms Explained
Few-Shot Learning (FSL): A machine learning paradigm designed to classify new data categories using only a handful of labeled examples (e.g., 3–5 samples per class), mimicking how humans learn from limited exposure. In healthcare, it addresses the scarcity of annotated medical images (e.g., rare diseases or niche conditions) by leveraging transferable features from pre-trained models or auxiliary data to generalize effectively.
Prototypical Network: A few-shot learning method that classifies new samples by comparing them to “prototypes”—average feature representations of each class derived from support samples (e.g., 3 MRI scans per tumor type). Classification is based on distance metrics (e.g., Euclidean distance) in feature space, enabling rapid adaptation to new classes without extensive retraining.
Grad-CAM (Gradient-weighted Class Activation Mapping): A visualization technique that highlights regions of an input image most influential for a model’s prediction by backpropagating gradients through the network’s final convolutional layer. The resulting heatmap reveals where the model focuses, aiding interpretability (e.g., identifying whether a chest X-ray model attends to a lung nodule or irrelevant background).
Explanation Alignment Loss: A custom loss function that quantifies the mismatch between a model’s attention (e.g., Grad-CAM heatmaps) and human-provided annotations (e.g., radiologist-marked tumor regions). By penalizing attention to clinically irrelevant areas during training, it steers the model toward diagnostically meaningful features, improving both interpretability and performance.
Joint Optimization Objective: A training strategy that balances multiple loss functions (e.g., classification accuracy and explanation alignment) via weighted summation. The weight (e.g., hyperparameter α) controls the trade-off between goals—here, ensuring the model prioritizes both correct predictions and clinically plausible attention patterns.
3-Way, k-Shot Learning: A few-shot learning setup where the model must distinguish among 3 classes (e.g., tumor types) using only k examples per class (e.g., 3-shot = 3 samples each). Episodic training simulates real-world scenarios by repeatedly presenting small, varied batches (”episodes”) to improve generalization.
Dice Similarity Coefficient: A metric (ranging 0–1) measuring spatial overlap between two regions, often used to compare model-generated attention maps (e.g., Grad-CAM) with expert annotations (e.g., segmented tumors). Higher values indicate better alignment; in this context, it quantifies how well the model’s focus matches clinical priorities.
Post-Hoc Explanation: Interpretability methods applied after model training (e.g., LIME, SHAP) to retroactively justify predictions, which may not reflect the model’s true decision-making process. Contrast with inherent interpretability, where explanations are embedded into training (as in this study) to ensure alignment with domain knowledge.
Episodic Training: A few-shot learning approach where models are trained on small, randomly sampled “episodes,” each mimicking a mini classification task (e.g., 3 classes × 3 samples). This simulates real-world scenarios with limited data per task and encourages rapid adaptation to new categories.
Support and Query Samples: In few-shot learning, support samples are the limited labeled examples (e.g., 3 annotated X-rays) used to define classes in an episode, while query samples are unlabeled examples the model must classify based on the support set. This mimics how clinicians diagnose new cases using a small reference set.